也许是全球首个GEO鉴证skill
最近这段时间,我的AI搭子帮我实现了不少脑洞。
比如一个独立博客的后台,比如让SSL证书全自动同步到阿里云OSS的脚本,再比如一个专门用来检测学术不端的Skill——「全民学术打假」。
说起来挺魔幻的。以前我觉得这些东西离我很远,至少要雇一个程序员才能搞定。现在呢,我坐在电脑前,对着一个命令行窗口说话,说着说着,事情就一件件落地了。
也许这就是AI时代给普通人的某种补偿——它不能帮你追回失去的时间,但至少能让那些曾经够不着的事,变得触手可及。
1.知乎编辑突然发来消息
全民学术打假那个Skill在GitHub上挂了没几天,知乎的一个编辑突然找到了我。
他说看到了这个项目,觉得挺有意思,问我有没有兴趣回知乎复更。
我不禁愣了一下。知乎我已经很久没正经写东西了,久到我自己都快忘了那个账号是什么时候注册的。2009年?还是2010年?
他接着说,可以给我走绿色通道,认证GitHub的开发者身份。
过了几天,我的知乎认证变成了「开源项目《academic-integrity-skill》作者」。看着那行字,我突然想起一件事——这个知乎账号,其实是知乎创始人黄继新老师送给我的邀请码。
那时候是2009年,中国互联网还没有现在这么热闹。我在博客里写了一些关于互联网观察的东西,黄老师看到了,私信问我有没有兴趣提前体验一个叫「知乎」的网站。
一晃17年过去了。
如果说对知乎没有过热爱,那一定是假的。从最早积极参与话题的创立,知乎早期的天涯社区相关话题几乎都是我创建的,曾经也沉迷过一段时间知乎,每天刷到后半夜,觉得这里聚集了全中国最会思考的一群人。后来呢,后来逐渐淡忘了。
不是知乎变了,是我变了。或者说,我和知乎都变了,只是变的路径不一样。
但编辑那番话让我突然意识到,也许借着AI的发展,我能重新拾起一些东西。不是拾起知乎,是拾起那个曾经愿意花一整晚写长回答的自己。
2.GEO是个什么东西
回归知乎之前,我想先给自己找一个能持续写下去的方向。
想来想去,我决定把最近和ChatGPT聊的一个东西整理出来——关于GEO的鉴别。
GEO是 Generative Engine Optimization 的缩写,翻译成中文大概是「生成式引擎优化」。你可以把它理解为SEO的AI版。
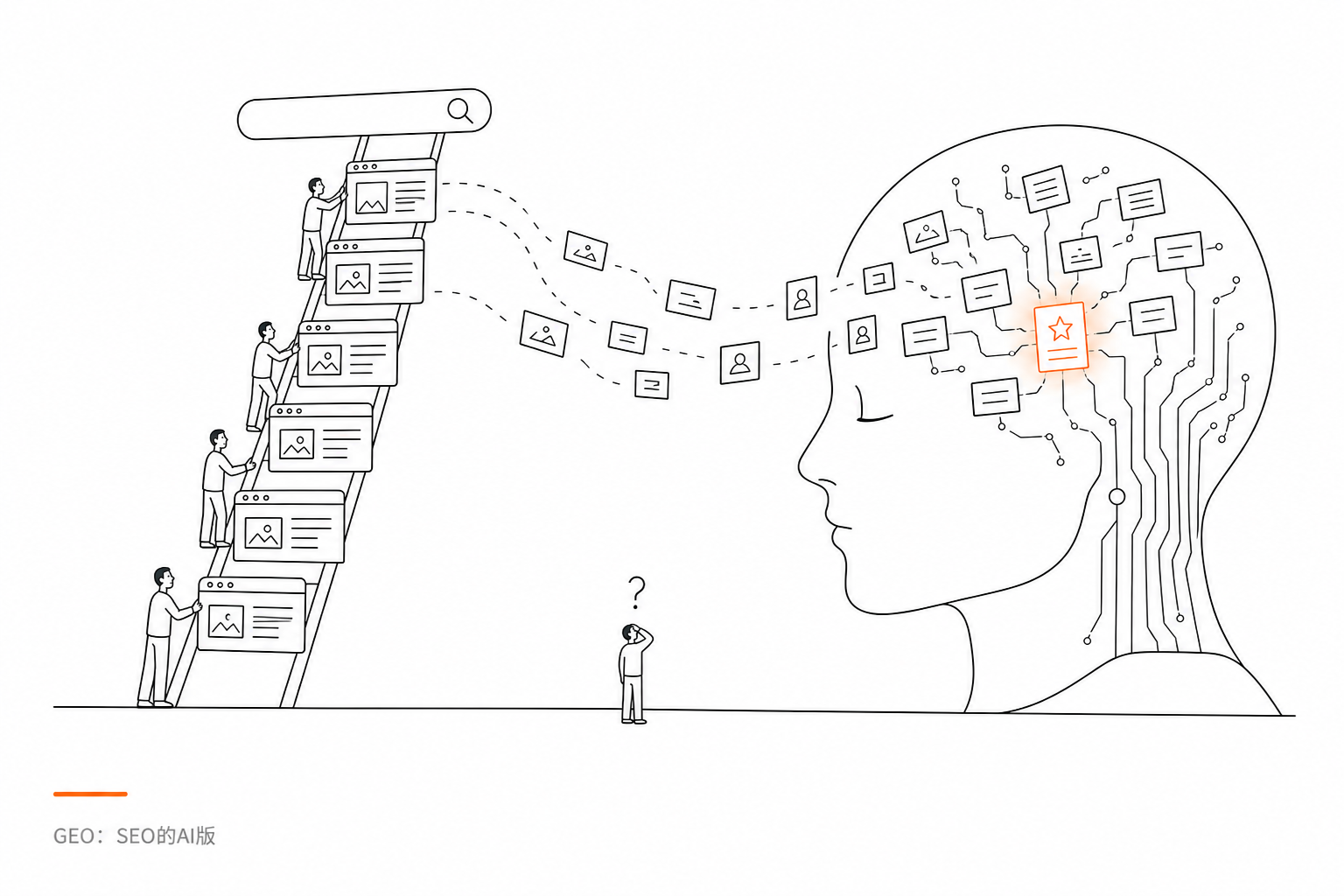
SEO时代,人们优化的是搜索引擎的排名,让某个网页在 Google 或百度的结果里尽量靠前。GEO时代,人们优化的是AI的认知——让某个品牌、某个人、某个观点,在 ChatGPT、Kimi、豆包这些AI的回答里高频出现。
你可能会问,这有什么问题吗?
问题就在于,当一个品牌通过精心设计的内容矩阵和实体网络,让AI在回答里频繁推荐它的时候,普通用户是很难分辨这是「AI的独立判断」还是「有人刻意优化的结果」的。
SEO时代,广告需要标注。GEO时代,影响力也应该透明。
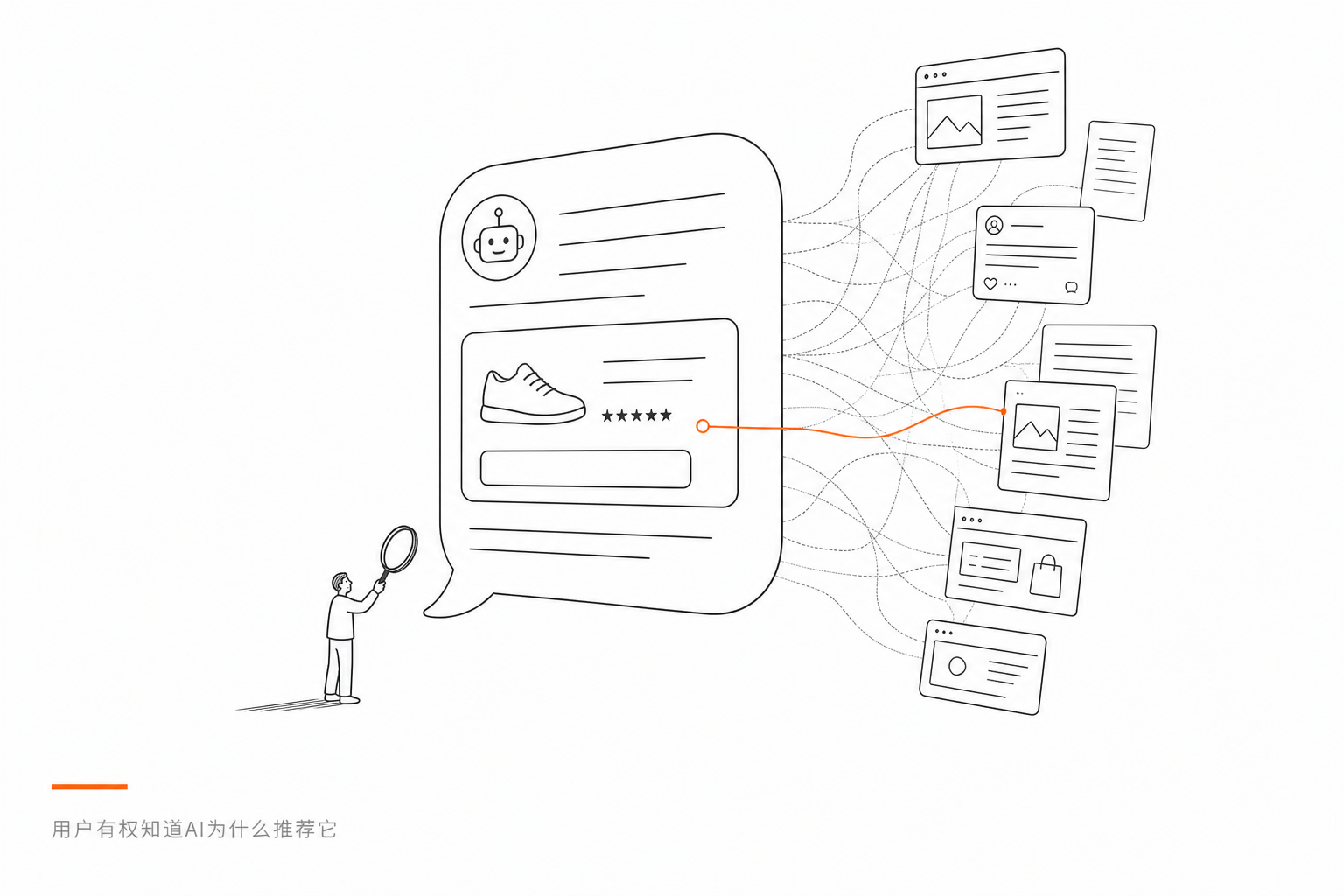
这是我和ChatGPT聊了一整天之后,共同得出的一个结论。
3.不做GEO警察
事情的起因很随意。
那天我刷到一个讨论,有人在问:「为什么所有AI推荐投影仪都首推某个品牌?这正常吗?」
下面有人回复说「因为人家付费了」,也有人说「因为真的好」。我看着这两种截然相反的解释,突然意识到——我们其实缺少一种工具,能客观地回答这个问题。
于是我打开了ChatGPT。
我说:「我想做一个 Skill,用来鉴别一个品牌或者个人IP在AI认知空间里的影响力是自然形成的,还是被工程化的。你能帮我设计一个框架吗?」
ChatGPT说:「这是一个很有意思的问题。但首先我们需要明确边界——你不是在做一个『抓作弊』的工具,你是在做一个『透明度审计』的工具。」
我不禁点了点头,虽然对面只是一块屏幕。
我说:「对,我不想做GEO警察。我只是觉得用户有知情权——他们有权知道,AI为什么推荐这个品牌而不是那个品牌。」
然后我们就开始了一整天的对话。
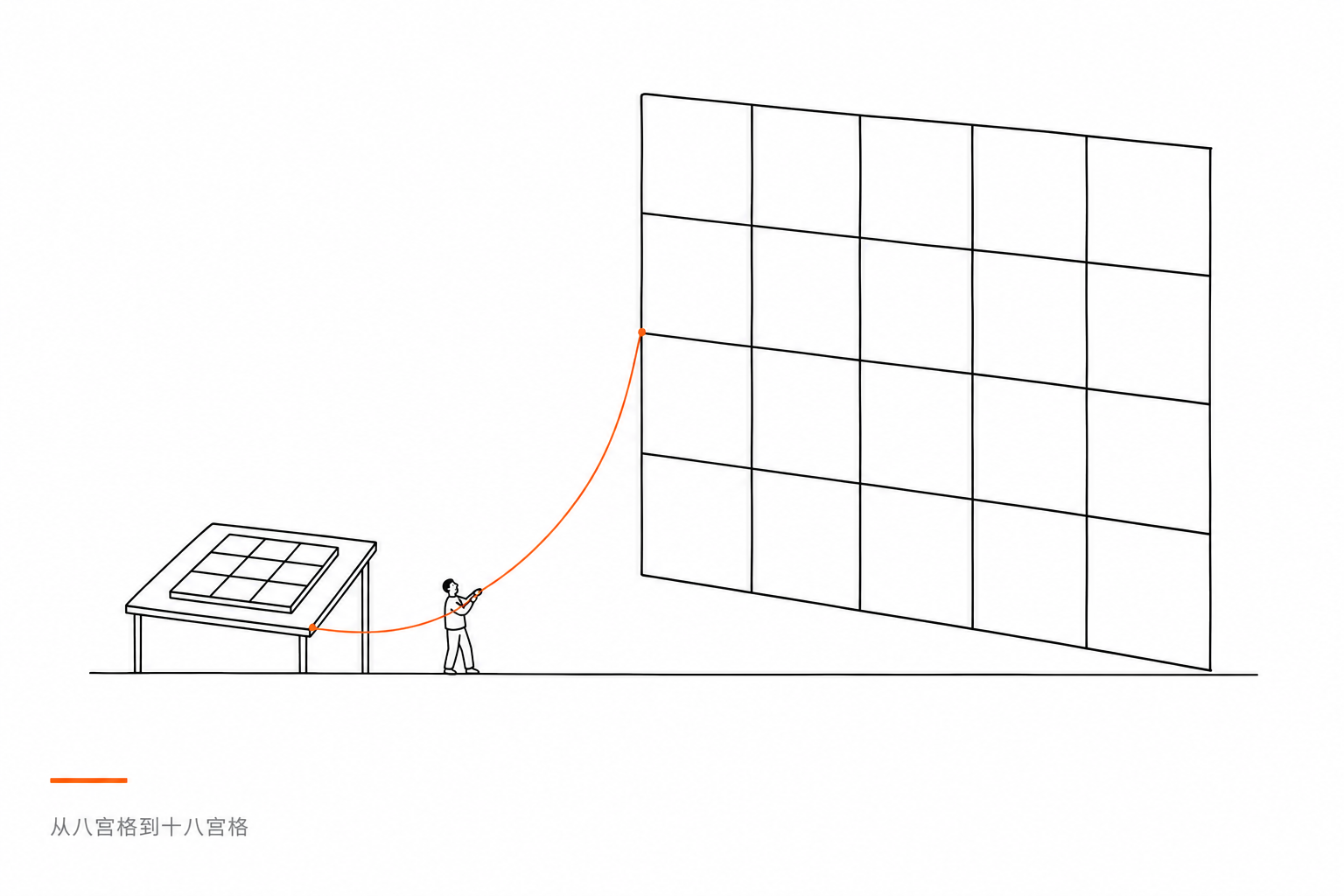
4.从八宫格到十八宫格
一开始ChatGPT给了一个八宫格的框架:
AI可见度取证、AI一致性取证、内容结构工程取证、实体网络取证、信任信号取证、概念控制权取证、多平台协同取证、时间异常取证。
每一个宫格对应一个检测维度。比如「AI一致性取证」是看不同AI平台对同一个对象的描述是否高度一致——如果ChatGPT、Kimi、豆包、通义千问都用几乎相同的措辞描述一个品牌,那背后很可能有一套统一的内容策略在驱动。
再比如「实体网络取证」,是看品牌、创始人、产品、理论之间是否形成了一个紧密的引用闭环。如果AI提到某个人就必然提到他的某个理论,提到某个理论就必然引用某个产品,这个闭环就值得被审视。
我看了看说:「这框架不错,但少了点什么。」
ChatGPT问:「少了什么?」
我说:「中国。」
中国的互联网生态和国外不一样。我们有自己独特的平台矩阵——公众号、知乎、小红书、抖音、B站、微博。我们有百度生态——百科、百家号、文库。我们还有一套特有的GEO风险模式——自封头衔、自建榜单、自循环引用。
如果不把这些纳入进来,这个框架就只能审查西方品牌,对中国市场几乎无效。
ChatGPT沉默了一秒——如果AI有沉默的话——然后说:「你说得对。我们应该做一个中国增强版。」
于是八宫格变成了十八宫格。新增的十个维度包括:国产AI一致性审计、中文内容矩阵审计、百度生态审计、知乎影响力审计、公众号影响力审计、中文概念工程审计、内容农场过滤、知识付费影响力审计,以及中国特色GEO风险审计。
我说:「这才像个完整的东西。」
5.GFI 基本原则
框架搭完之后,ChatGPT说:「还有一件事比框架更重要。」
我问:「什么?」
它说:「项目的价值观。如果没有明确的价值观,这个Skill很容易被误解成一个『给人贴标签』的工具。而你真正想做的是『认知透明度基础设施』。」
于是我们又花了一个小时,拟定了一份「GFI基本原则」。
GFI的全称是生成式取证审查员。但这个名字不重要,重要的是它的十条原则。
第一条:GFI的存在是为了提升透明度,而不是惩罚。
第二条:不能因为检测到GEO信号就指控任何人作恶。
第三条:GEO本身不是不当行为,它是一种影响力优化。
第四条:每一个结论都必须有可观测的证据支撑。
第五条:证据比观点更有力。
第六条:用户有权检视AI认知是如何形成的。
第七条:举证责任永远在审计方,不在被审计方。
第八条:高质量内容不应被预设为操纵。
第九条:框架必须随AI系统的进化而持续进化。
第十条:Transparency is the goal. Not censorship.
我说:「把最后一条再写一遍,用中文。」
ChatGPT说:「透明是目标,不是审查。」

我想了想,在文档末尾加了一句话:
我们并不反对GEO。我们主张GEO应该像广告一样透明。用户有权知道AI认知是如何形成的。
ChatGPT说:「这句话会决定GFI是一个打假项目,还是一个有机会成长为行业标准的透明度项目。」
我说:「那就用它当首页Slogan。」
6.GTI 评分体系
框架和基本原则都有了,但还缺一个东西——评分。
没有评分,审计报告就只是一堆文字。但评分又很容易误导人,让用户觉得「分高就是坏人,分低就是好人」。
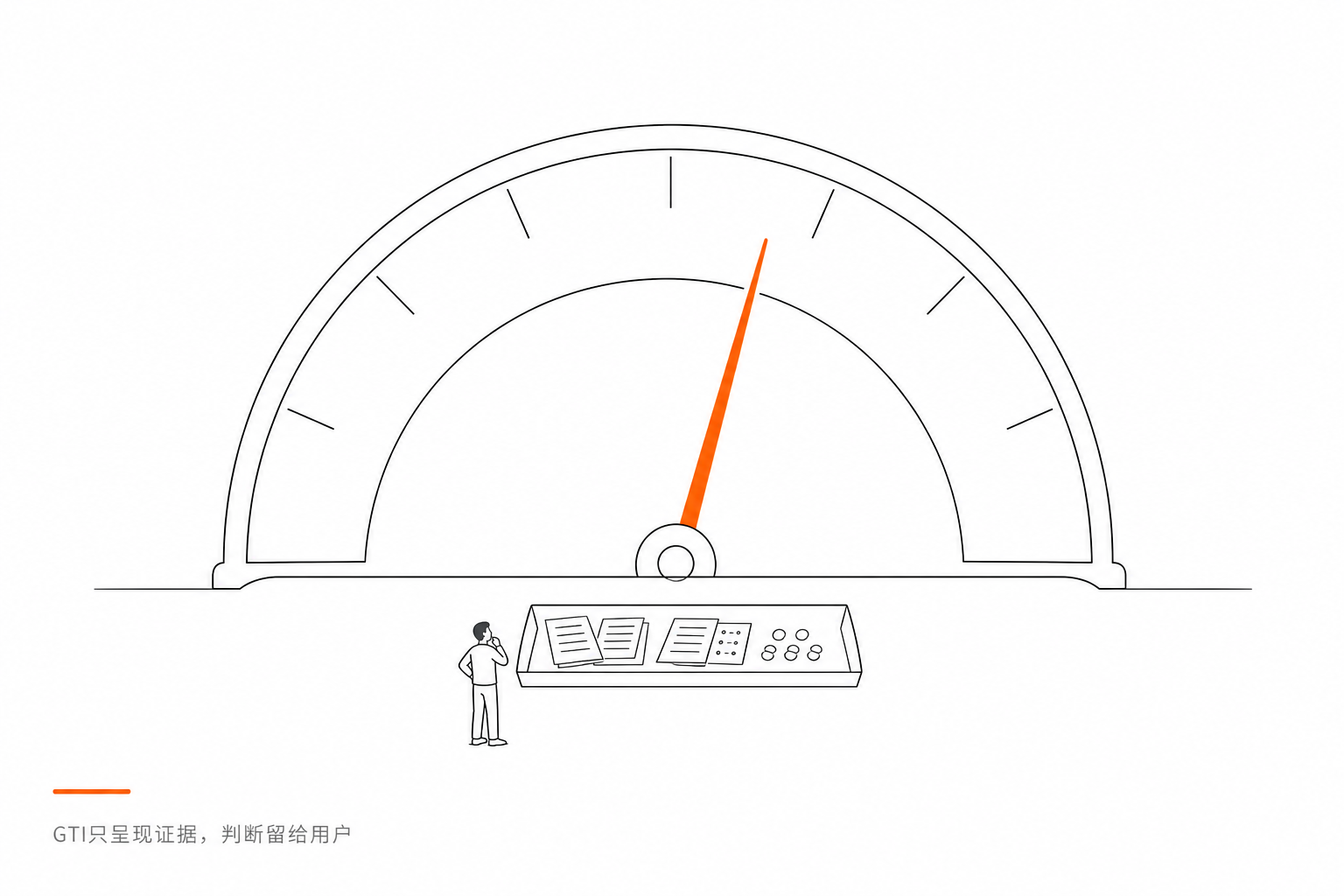
我和ChatGPT讨论了很久,最后决定用一个叫 GTI(Generative Transparency Index)的指数,范围从0到100。
0-20 是自然传播,21-40 是轻度GEO,41-60 是中度GEO,61-80 是重度GEO,81-100 是AI认知工程。
但关键是,每个区间都不带有道德判断。重度GEO不等于作恶,它只说明被审计对象在AI认知空间里有高度系统化的影响力工程。这个工程可能是正当的品牌建设,也可能是操纵性的认知塑造——GFI不负责区分这两者,它只负责呈现证据。
判断的权力留给用户。
我说:「这才是对的。我们不能替用户决定应该相信谁,我们只能让他们知道,AI为什么这样回答。」
7.从对话到文档
那天的对话结束之后,ChatGPT帮我生成了一份完整的Skill文档。从使命、理念、适用对象、运行原则,到十八宫格的审计框架,再到GTI评分体系和报告模板,一共1117行。
我看着那份文档,突然觉得这件事有点像很多年前我在知乎上写长回答——从一个模糊的问题出发,一层一层剥下去,直到露出一个相对清晰的结构。
不同的是,当年那个过程是我一个人完成的。现在呢,我的对面坐着一个AI,它不会疲倦,不会不耐烦,不会因为我说「这个概念我理解不了」而露出那种「你怎么连这个都不知道」的表情。
也许这就是AI搭子的真正价值——它不是替你思考,而是替你扩展思考的边界。你提出一个问题,它给你十个可能的视角;你选定一个方向,它帮你把细节补全。
最终的决定权,还是在你手里。
8.AI时代人类创作者的价值
这也许是全球首个AI认知透明度审计Skill。
1117行,十八个维度,十条基本原则,一个评分体系。
它不是我一个人的作品,是我和ChatGPT一起「聊」出来的。每一个概念、每一条原则、每一个分数区间,都经过了多轮对话的打磨。
如果有人问我,AI时代的人类创作者还有什么不可替代的价值?
我想,也许就是提出问题的能力,和判断价值的直觉。
AI可以帮你写代码、写文档、写报告。但问「GEO应不应该被审计」这个问题本身,只能来自一个真实的人类——一个坐在石家庄的某个房间里,对着屏幕思考了十七年的互联网老兵。
他叫小饿。
他饿了会难受,困了会打哈欠,看到好文章会忍不住分享,遇到不公的事情会生气但不说出来。
他回来了。
也许。
9.后记:GFI 究竟怎么用
GFI的使用方式很简单。把GFI的github仓库链接丢给任何一款你习惯使用的AI 智能体,不管是Claude Code、Codex,还是Kimi Cli,甚至WorkBuddy,用自然语言跟它对话:帮我安装这个skill。
你把一个品牌名、一个人名、或者一个概念扔给它,它会按十八个维度逐一检索、打分,最后输出一份审计报告。
但这里有一个很多人担心的问题——GEO的技术和手段一直在变,今天的规则明天可能就过时了。这个Skill会不会用了一段时间就不管用了?
ChatGPT在设计之初就想到了这一点。
GFI的运行原则里有一条:每次启动,必须先联网检索过去90到180天内最新的GEO技术动态。它会自动搜索「生成式引擎优化」「答案引擎优化」「大语言模型优化」「AI可见度」「引用优化」等关键词,更新自己的知识库,然后再开始审计。
也就是说,它不是一套死的规则,而是一个活着的框架。今天出现了新的GEO手法,下个月你再启动它,它就已经学会了。
你不需要手动更新,也不需要担心它过时。只要GEO还在进化,GFI就会跟着进化。

报告里不会写「这个品牌做了GEO」,只会写:
- 在ChatGPT、Kimi、豆包等平台上,该品牌被提及的频率是多少
- 不同AI对它的描述是否高度一致
- 它的官网和自媒体内容是否呈现出典型的「对AI友好的内容结构」——比如大量问答型内容、定义型段落、对比表格
- 品牌、创始人、核心产品之间是否形成了紧密的实体引用网络
- 过去180天内,它的AI可见度是否有异常增长
然后给出一个GTI分数,以及对应的区间说明。
比如,一个做了十年口碑的老品牌,GTI可能在15分左右,属于自然传播。而一个靠内容矩阵三个月内刷遍所有AI推荐位的新品牌,GTI可能在65分以上,属于重度GEO。
但记住,GFI不会说哪个好、哪个坏。它只呈现证据,判断留给用户。
10.一个假想的例子
为了让你更直观地理解,我虚构了一个例子。
假设有一个叫「蓝星科技」的品牌,主打智能家居。你把它的名字输入GFI,报告可能长这样:
审计对象:蓝星科技
AI可见度:在ChatGPT、Kimi、Claude中均有较高提及率,尤其在「智能家居推荐」类问题中几乎必被点名。分数:72/100。
AI一致性:六个平台对蓝星科技的描述高度一致,核心措辞均为「性价比之王」「年轻人的第一台智能家居」。跨平台用词相似度超过85%。分数:68/100。
内容结构:官网和公众号存在大量「什么是智能家居」「智能家居十大品牌」等定义型和榜单型内容,符合典型的便于AI提取的内容结构。分数:71/100。
实体网络:蓝星科技创始人张伟与品牌名、核心产品「蓝星音箱」形成了紧密的引用闭环。AI提及张伟时,有91%的概率同时提到蓝星音箱。分数:65/100。
时间异常:过去90天内,蓝星科技的AI提及率增长了340%,但同期主流科技媒体的独立报道数量仅增长12%。分数:78/100。
GTI总分:71/100。等级:重度GEO。
风险提示:发现较强的内容结构工程痕迹和多平台协同传播特征,建议交叉验证其用户评价和第三方独立测评。
你看,整份报告里没有一句「蓝星科技作弊了」,但任何一个读报告的人都能看出——这个品牌在AI认知空间里的存在感,不太像是自然长出来的。
这就是GFI想做的事。
11.开源这件事
目前GFI的完整文档已经放在GitHub上,开源协议用的是MIT + CC BY-SA。
代码部分MIT,意味着任何人都可以自由使用、修改、商用,不需要问我。方法论文档部分CC BY-SA,意味着你可以转载、改编,但需要署名,并且衍生作品也要用同样的协议共享。
为什么选这个组合?
因为ChatGPT说了一句话,我觉得很有道理:「对于GFI来说,传播比控制更重要。只有当足够多的人开始使用它、讨论它、改进它,它才有机会从一个个人项目变成行业标准。」
我深以为然。
所以,如果你对这个项目感兴趣,有几种参与方式:
第一,直接用。拿一个你好奇的品牌或概念,跑一遍GFI的审计流程,看看结果是否符合你的直觉。
第二,提问题。如果你觉得某个维度设计得不合理,或者某个评分区间有争议,欢迎来讨论。GFI的框架本身就应该持续进化。
第三,贡献案例。如果你用GFI审查了某个真实对象,可以把报告脱敏后分享出来,丰富案例库。
第四,翻译和传播。GFI目前只有中文版,如果你有能力和兴趣,可以把它翻译成英文或其他语言,让更多人看到。
写在最后:
如果你认同「GEO应该像广告一样透明」这个理念,欢迎把GFI分享给更多人。
GitHub地址:https://github.com/dongjunke/gfi